The tech world is buzzing after Andrej Karpathy suggested moving to structured Wikis. The hot take? “RAG is dead.” But the real “elephant in the room” isn’t RAG itself-it’s our obsession with rigid domain schemas.
A recent post by Andrej Karpathy sparked widespread debate when he suggested that instead of “salami-slicing” documents into fragments for Retrieval-Augmented Generation (RAG), developers should organize data into an LLM-maintained Wiki. Because a Wiki structure adds more organization than simple text slices, a flurry of articles began proclaiming that traditional “RAG” is dead.
However, arguing over RAG versus Wikis misses the deeper architectural flaw in our data pipelines. The true “elephant in the room” has always been the rigid necessity of a predefined domain schema or ontology.
To truly understand how to fix modern AI queries, we must trace how data evolves from raw text to a final answer, and look at the catastrophic loss of information that occurs when we impose a domain ontology too early in the process.
The Starting Point: Unstructured Documents
The journey of any knowledge retrieval system begins with a messy reality: unstructured documents.
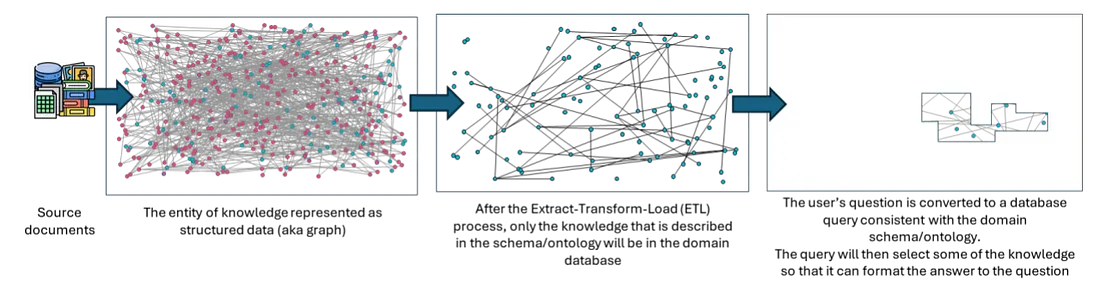
In their original state, these sources contain an abundance of interconnected facts. For example, a corpus of historical documents might contain details about 20th-century presidential history, Kennedy family genealogy, and regional geopolitical conflicts like the Cold War. At this raw stage, no data is lost; everything is available.
The Traditional Path: The “Just-In-Case” Lossy Sieve
In the conventional data flow model, developers use a domain-driven Extract-Transform-Load (ETL) approach to convert these unstructured documents into a queryable database.
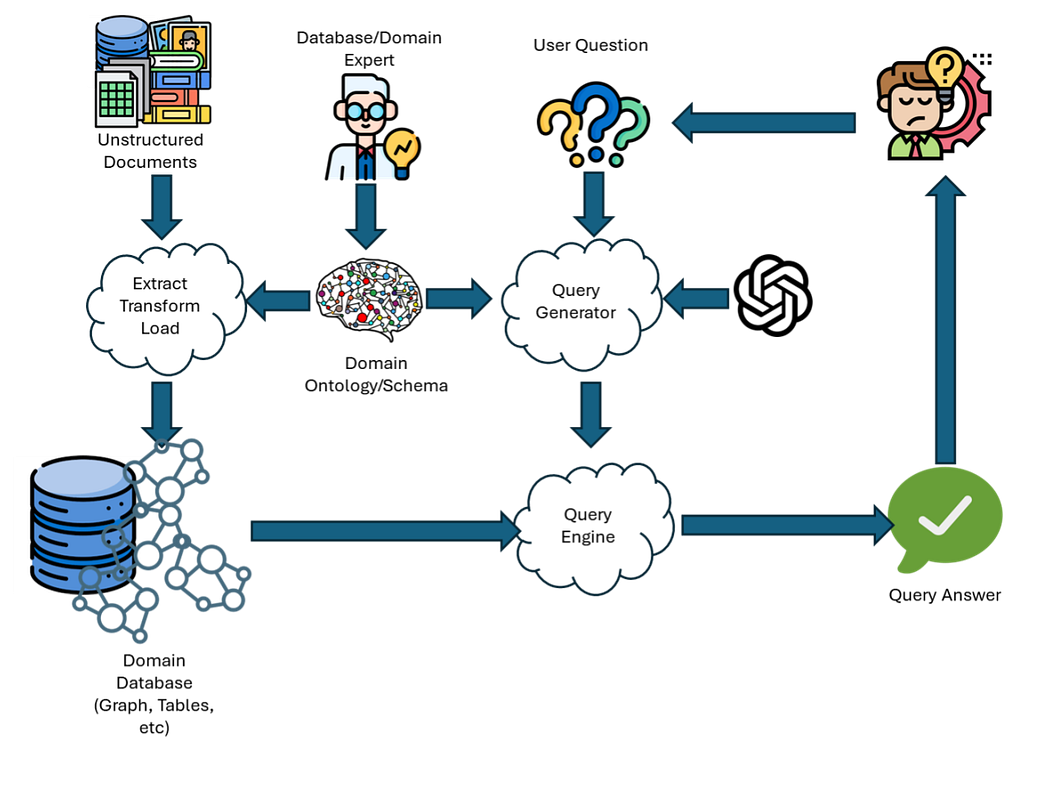
Here lies the critical flaw: a database expert must define the exact structure of the knowledge before the data is extracted. When the ETL process runs, any knowledge from the source documents that does not have a specific place in the predetermined domain ontology is simply discarded. Only the knowledge explicitly described in the schema will ever make it into the domain database.
This is a “just-in-case” approach. Facts are heavily filtered and formatted into a specific domain schema just in case a user asks a question about them later. If the user’s future questions require facts that didn’t fit the schema, those facts are already gone.
The Query Stage: Where Rigid Systems Break
To understand the consequence of this early data loss, let’s look at the query stage. In the traditional model, a user’s question must be translated into an exact database query (like Cypher or SPARQL) that aligns perfectly with the domain schema.
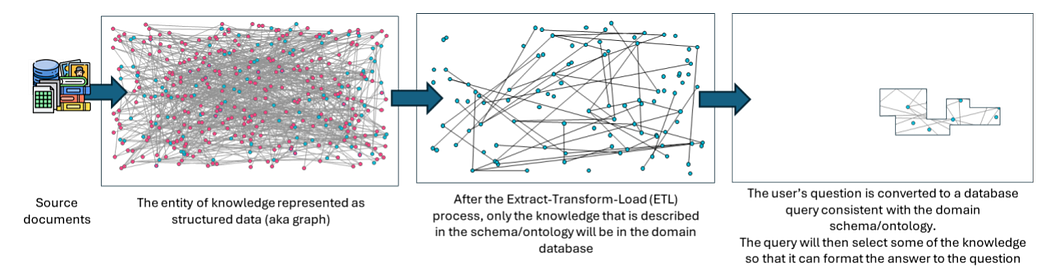
Imagine the user expresses an initial interest in Kennedy family history, so the database expert creates a genealogical domain ontology. The ETL-to-graph process runs over the source documents, dropping everything except family connections to create a lossy data model.
When the user asks, “How is Jack Schlossberg connected to JFK?”, the system works flawlessly. The Query Generator matches the genealogical database structure, traverses the parent/child/spouse paths, and successfully returns the answer.
But what happens when the user follows up with: “How was the USA affected by the Cuban Missile Crisis?”.
Even though the historical context of the Cuban Missile Crisis was present in the original books and documents, it fell outside the genealogical domain. Because the ETL process was lossy, those geopolitical facts were discarded during extraction.
The query engine cannot answer the question, and the user is forced to start the entire expensive and time-consuming ETL pipeline over again with a new schema.
The Dedoctive Alternative: Loss-less and Schema-less
If defining an ontology too early causes data loss, the solution is a domain-less, schema-less, and loss-less approach.
Instead of filtering data through a strict ontology, a system like Dedoctive extracts and indexes all possible knowledge from the unstructured sources into a universal Knowledge Model.
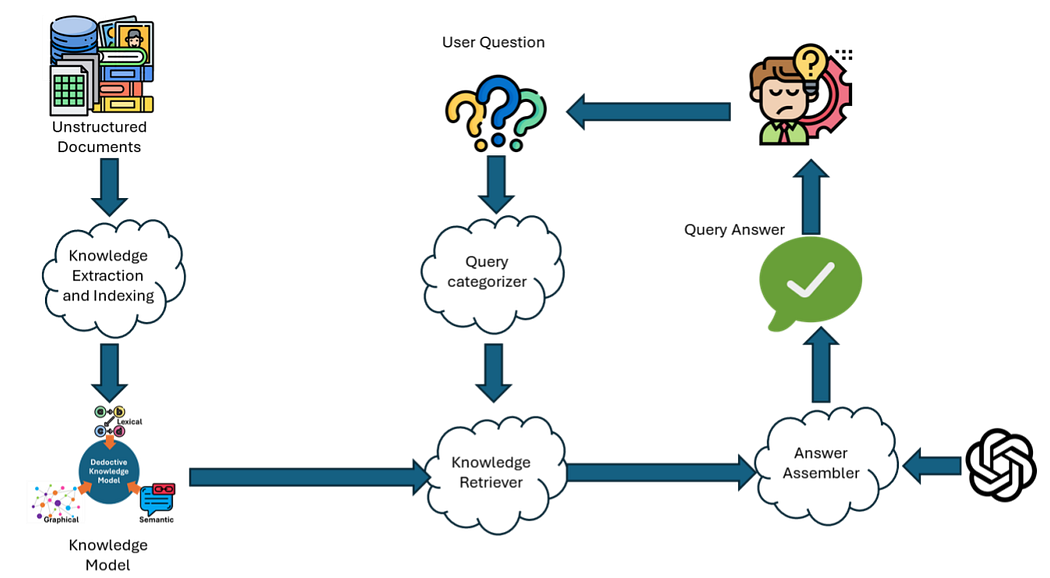
Because this transformation does not rely on a schema, it is completely loss-less. Nothing is thrown away simply because it didn’t fit a predetermined category. Furthermore, because there is no rigid database structure to alter, new sources can be added incrementally without requiring a completely new ETL process.
“Just-In-Time” Answer Assembly
How do you query a system that lacks a rigid schema? The answer lies in delaying the structuring of data until the exact moment a question is asked.
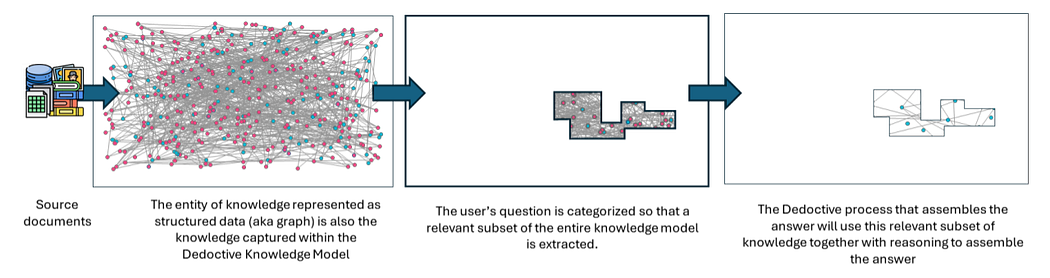
When a user asks a question, their query is categorized so that the appropriate subset of the massive knowledge model can be retrieved. Crucially, this does not require any prior knowledge of a domain or schema.
Once the relevant, un-filtered facts are extracted, an Answer Assembler utilizes an LLM reasoner to synthesize the final answer.
Instead of forcing data into a domain “just-in-case” it is needed, the relevant facts are determined “just-in-time” before the answer assembler processes them. The system ends up using the same facts as a traditional ETL query, but leaves the conversion of that knowledge into a specific domain until the very moment it is required.
Just-in-Time vs Just-in-case step-by-step example
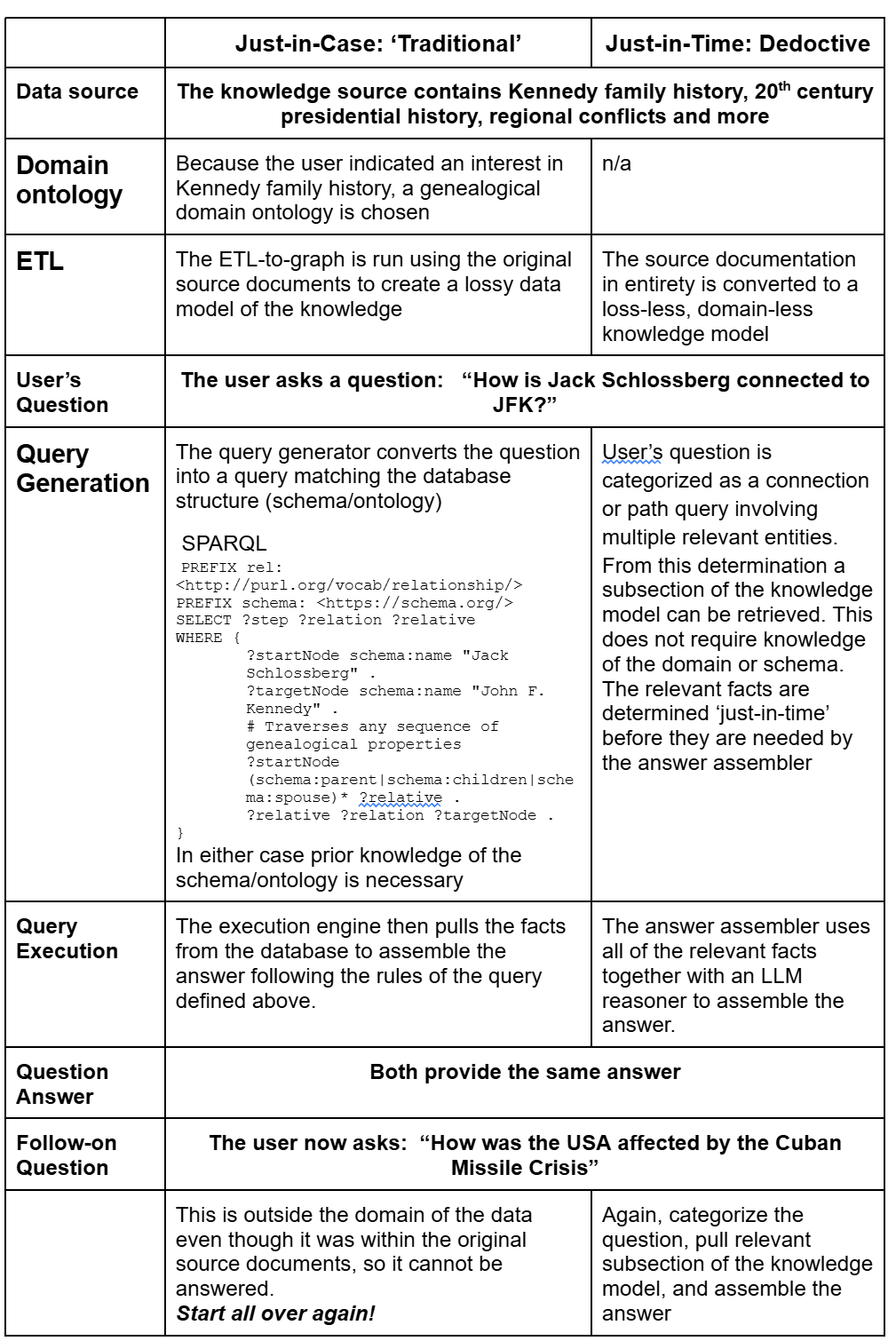
How Does Just-in-Time Architecture Alter the Landscape?

Conclusion: Beyond the Wiki
Andrej Karpathy’s suggestion to organize unstructured text into a Wiki is a great step forward because it provides an organizational structure without losing data, offering the same domain-less, schema-less, and loss-less flexibility.
However, a schema-less Knowledge Model like Dedoctive takes this a step further. By incorporating advanced query characterization and specialized retrievers, it allows for the precise selection of relevant facts required to reason out complex answers.
RAG isn’t dead, but our habit of slicing documents into fragmented, rigid databases needs to end. By abandoning early-stage domain schemas in favor of loss-less knowledge models, we can stop throwing valuable data away and begin answering questions with true, just-in-time reasoning.
Author
Peter Lawrence is a passionate and innovative senior technologist who delivers transformational solutions to strategic technical challenges at enterprise level.
Peter has founded and led several startups as CTO.
At Matrikon, which was acquired by Honeywell, Peter led all software and information technology developments, transforming the software platform from an expensive-to-maintain legacy system to a Lean system focusing on added-value and utilizing third-party technology where possible.
Peter also transformed the development processes from traditional but inefficient waterfall development to Agile methodology.
Before that, as President and founder of Resolution Integration Solutions, Peter led the creation of Resolution, an innovative database model application for the process manufacturing industries.
Other positions Peter has held included Director of Technology at Morrison Knudsen, Vice President at KBC Advanced Technology, Technical Director and founder of KBC Process Automation, and a founder of Process Automation and Computer Systems Ltd.
More information
Email Peter Lawrence: peter.lawrence@dedoctive.ai
Leave a Reply
You must be logged in to post a comment.